To follow that star
no matter how hopeless,
no matter how far,
to fight for the right
without question or pause,
to be willing to march,
march into hell
for that heavenly cause
— An extract from “Mad men are children of God” by Dale Wasserman
We are going to discuss the CAP theorem. To recap: CAP theorem in distributed systems means that a distributed system can deliver only two of three desired characteristics: consistency, availability, and partition tolerance (the ‘C,’ ‘A’ and ‘P’ in CAP). For more details about the above terms, I would recommend visiting the Part 1 of the blog over here.
Coming back to CAP theorem, as stated above the it is possible to achieve a consistent and available system but it can’t partition tolerant or a available and partition tolerant system but it won’t be consistent and a consistent and partition tolerant system but it cannot be available all the time. Let’s take all the scenarios and verify the CAP theorem once.
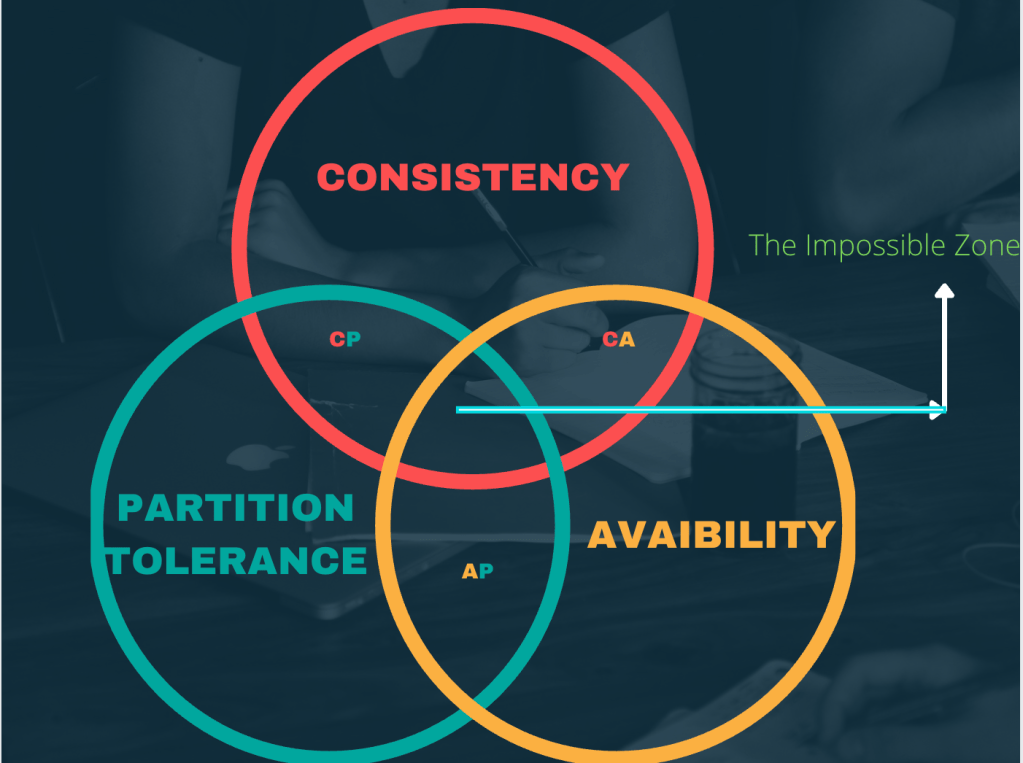
CA(Consistent and Available System)
Assume a database is CA i.e. all the nodes show the same consistent data and it is available at all times, now if we run into the issue with fault at a particular node. There are two potential scenarios to handle that –
- Allow all the nodes including the faulty node to be available
- This allows the system to be available at all times
- However, the data present at the faulty node might not be same as the data present at normal node which eventually sacrifices consistency
- Allow only the normal nodes to be available
- If the query comes to any available node, same result is ensured
- If the query comes to faulty node, we are required to return that this particular node is not available and hence compromises availability.
AP(Available and Partition Tolerance System)
Assume a database is AP i.e. all the nodes are available at all times and the cluster is functional even with a faulty node.
Let’s try to enforce consistency in the above scenario. If someone queries the faulty node and it has to be consistency with the other nodes, it has to respond that it cannot answer the above query correctly and need to fix that node before answering to the query. This effectively makes the system unavailable for that node or compromises availability
CP(Consistent and Partition Tolerance System)
Assume a database is CP i.e. all the nodes show the same consistent data and the cluster is functional even with a faulty node.
Again let’s try enforcing availability when there is a fault at a particular node and we query that node
- Allow all the nodes including the faulty node to be available
- This allows the system to be available at all times
- However, the data present at the faulty node might not be same as the data present at normal node which eventually sacrifices consistency
CAP system still remains an impossible dream for a developer. There has been some other workarounds like eventual consistency etc that almost achieves this dream but it is yet to realized fully. Even with the recent database like DynamoDB, we are not able to get CAP theorem. Thank you all for reading this blog. Please send me any feedback on the above blogs.
